A Beginner’s Guide to DBT (data build tool) — Part 4: DBT — Automation, Test and Templating
Welcome to my fourth episode on the #dataseries!
Previously — on my #dataseries
1. A Beginner’s Guide to DBT (data build tool) — Part 1: Introduction
2. A Beginner’s Guide to DBT (data build tool) — Part 2: Setup guide & tips
3. A Beginner’s Guide to Apache Airflow — Part 3: Intro and Setup

1. Important Concepts
1.1 Incremental
Before jumping to the incremental model, let’s try to understand.
What is a model?
Model is one of the key components in your dbt project. Each model is a select statement, and defined in a .sql file. The file name is used as the model name. Linking back to my example, the daily_order_count.sql is a model.
What is an incremental model?
Incremental models are built as tables in your data warehouse. It inserts into the table that has already been built (for example: the target table is daily_order_count in BigQuery). As such, on each dbt run, your model gets built incrementally.
“Using an incremental model limits the amount of data that needs to be transformed, vastly reducing the runtime of your transformations. This improves warehouse performance and reduces compute costs.”
1.2 Variables
Imagine you need to generate a daily report before 10 AM everyday. Visiting each of those .sql to edit will be super time-consuming and error-prone. Therefore, we should replace the actual date with a variable that could be used across multiple models within a package. That variables will be changed and passed into the DBT run command each day those reports are generated.
Reusable Macro is one of the key power of using dbt. To find out more about other powers of DBT, visit my first episode here.
2. The problem
Scenario: I want to find out the number of orders per day before 10AM every morning, and I want to represent the result in a dashboard (Looker or Tableau for example). Therefore I have to create a table named as daily_order_count with the following schema: shipping_date in date format, andnum_orders in int64 format. This table will serve as an input for Looker or Tableau, but I will leave this BI tools for a future exploration.
3. The usual workflow
Usually you will write an insert statement from your BigQuery UI as shown in the diagram below. Then you click button Run to execute your sql command.
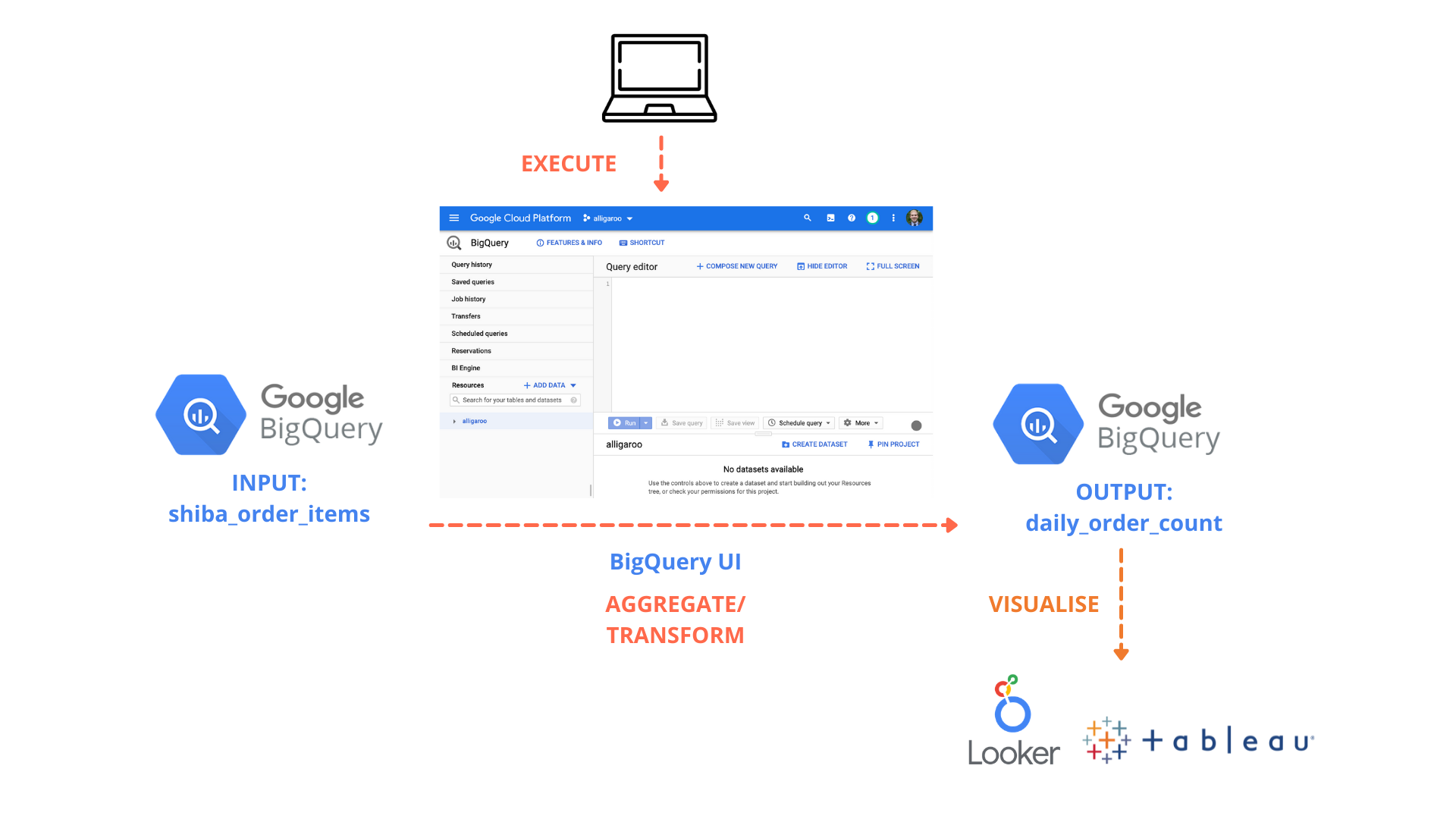
Demo
Step 1 — Create table daily_order_count

Step 2 — Check if the tabledaily_order_count is empty
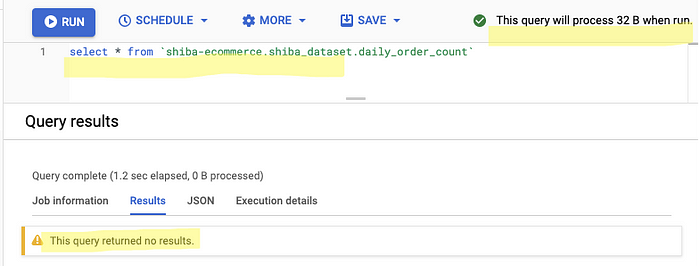
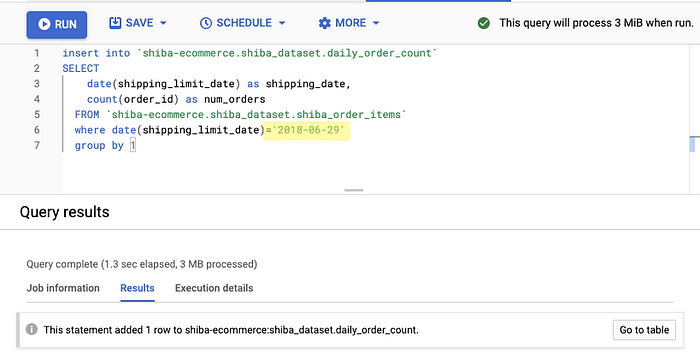
Step 3 — Insert values into the table daily_order_count
Run this query
insert into `shiba-ecommerce.shiba_dataset.daily_order_count`SELECT
date(shipping_limit_date) as shipping_date,
count(order_id) as num_orders
FROM
`shiba-ecommerce.shiba_dataset.shiba_order_items`
where
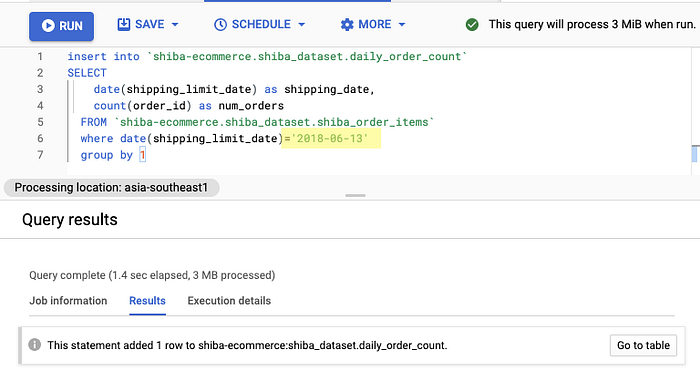
date(shipping_limit_date)='2018-06-13'
group by 1
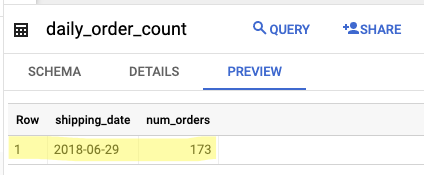
Inserting values where date(shipping_limit_date) = '2018-06-29'
Inserting values where date(shipping_limit_date) = '2018-06-12'
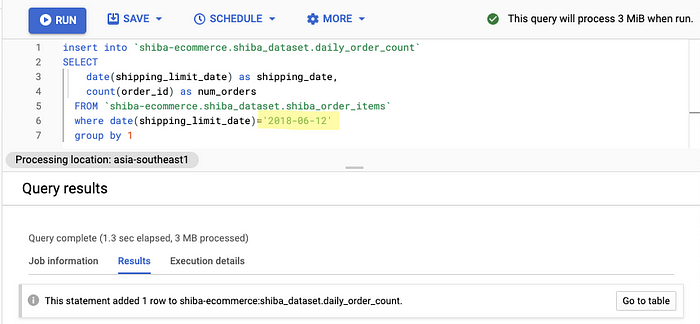
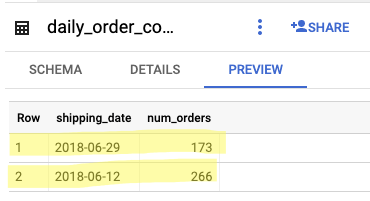
Inserting values where date(shipping_limit_date) = '2018-06-13'
Take note:
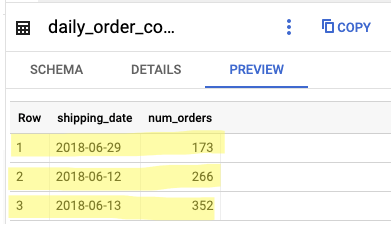
Runagain the previous statementwhere date(shipping_limit_date) = '2018-06-13'Take note: Now your
daily_order_counttable should look like this: duplicated values in row 3 and row 4 where neithershipping_datenornum_ordersis unique.

Visiting each of those .sql to edit will be super time-consuming and error-prone. Hence, dbt comes in place.
4. Dbt In Action

Now instead of manually running from BigQuery UI, we build dbt models (as .sql files) and let dbt take care of the rest. This is useful when you want to automate things and minimise human-prone errors. dbt can either be run from your laptop (local machine) or from another orchestration tool (Airflow). In this example, we will focus on the former. We will touch on the latter in the next episode.
Let’s delve into how dbt can help with the scenario above illustrated in point 2.
4.1 dbt run
Step 1 — Truncate the entire table daily_order_count
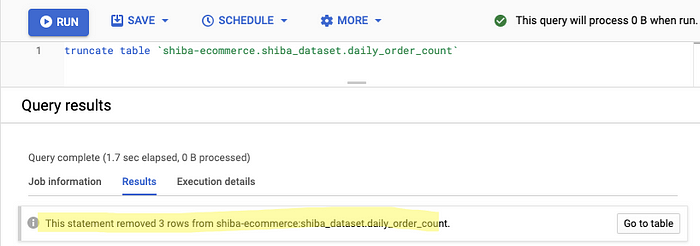
Step 2 — Check if the tabledaily_order_count is empty
Step 3 — Create a daily_order_count.sql file in your directory your-project-name/models/daily_order_count.sql . The sql file name must be exactly the same as the table name in BigQuery, which is daily_order_count .
Step 4 — Copy the following query into your daily_order_count.sql
SELECT
date(shipping_limit_date) as shipping_date,
count(order_id) as num_orders
FROM
`shiba-ecommerce.shiba_dataset.shiba_order_items`
where
date(shipping_limit_date)='{{ var("ingestion_date") }}'
group by 1Take note: Comparing to the SQL you ran just now, we removed the
insertstatement and changed from hardcoding theshipping_limit_datevalues to avariable'{{ var("ingestion_date") }}'.
i̵n̵s̵e̵r̵t̵ ̵i̵n̵t̵o̵ ̵`̵s̵h̵i̵b̵a̵-̵e̵c̵o̵m̵m̵e̵r̵c̵e̵.̵s̵h̵i̵b̵a̵_̵d̵a̵t̵a̵s̵e̵t̵.̵d̵a̵i̵l̵y̵_̵o̵r̵d̵e̵r̵_̵c̵o̵u̵n̵t̵`̵SELECT
date(shipping_limit_date) as shipping_date,
count(order_id) as num_orders
FROM
`shiba-ecommerce.shiba_dataset.shiba_order_items`
where
date(shipping_limit_date)='̵2̵0̵1̵8̵-̵0̵6̵-̵1̵3̵'̵ '{{ var("ingestion_date") }}'
group by 1
dbt provides a mechanism, variables to provide data to models for compilation. In this case, variables can be used to avoid hardcoding table names. To use a variable in the daily_order_count model, use the {{ var('...') }} function. More information on the var function can be found here.
Variables can be defined in 2 ways:
- In the
dbt_project.ymlfile - On the command line (CLI)
Take note: I will show you the latter way — on the command line because I think defining on CLI will be less troublesome compared to the former way where I have to edit the
shipping_limit_datein thedbt_project.ymlfile every to generate thedaily_order_countreport.
Step 5 — Open your Command Line and run dbt run
- Just some reference, I am using iTerm2 and I like it.
- Previously, we ran the
insertstatement to input values“2018–06–29”,“2018–06–12”, and 2 times“2018–06–13”consecutively.’ - Now we are going to use
dbt runto input such values into thedaily_order_counttable in such order. Run the followingdbt runone by one.
- Run
dbt run — models shiba_ecommerce.daily_order_count — vars ‘{“ingestion_date”: “2018–06–29”}’ - Run
dbt run — models shiba_ecommerce.daily_order_count — vars ‘{“ingestion_date”: “2018–06–12”}’ - Run 2 times
dbt run — models shiba_ecommerce.daily_order_count — vars ‘{“ingestion_date”: “2018–06–13”}’

dbt run — models shiba_ecommerce.daily_order_count — vars ‘{“ingestion_date”: “2018–06–29”}’
dbt run — models shiba_ecommerce.daily_order_count — vars ‘{“ingestion_date”: “2018–06–12”}’
dbt run — models shiba_ecommerce.daily_order_count — vars ‘{“ingestion_date”: “2018–06–13”}’Now the daily_order_counttable should look like this!
4.2 Dbt test
“DBT basically has two type of test built in: schema test (more common) and data test. The goal of writing DBT schema and data tests it to be an integrated part of the data architecture which saves time.
- In my first article — Part 1: Introduction, one of the power of dbt is Built-in testing for data quality.
- Now I am going to demonstrate what I meant. We will do the schema test.
- Schema tests are added as properties for an existing model (or source, seed, or snapshot). These properties are added in
.ymlfiles in the same directory as your resource. It returns the number0when your test passes.
Step 1 — Add a .yml file to your models directory. Example: models/schema.yml , and adjust the following content. FYI, In my case, I already have the schema.yml in the directory models/schema.yml so there’s no need to create the file.
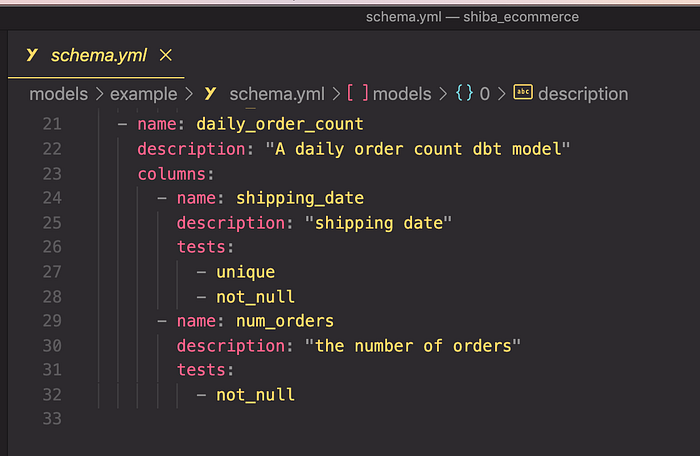
In plain English, these translate to:
The shipping_date column in the daily_order_count model should be unique and not contain null values. The num_orders in the daily_order_count model should not contain null values.
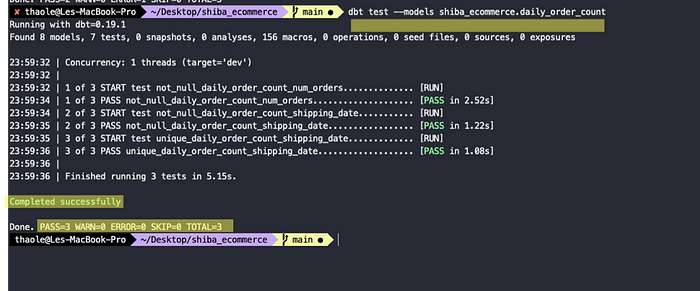
Step 2 — Run the dbt test command in your CLI
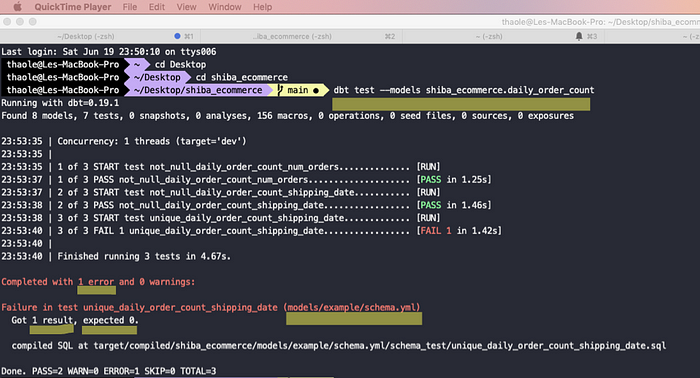
Run dbt test — models shiba_ecommerce.daily_order_count
The test failed with 1 error.
Reason: It failed the test because the shipping_date column is not unique. Because we have duplicated values in row 3 and 4 do you remember?
Completed with 1 error and 0 warnings:Failure in test unique_daily_order_shipping_date (models/example/schema.yml)Got 1 result, expected 0
Let’s remove row 3 and 4.


Now let’s run the test again.
Yay it passes now!
Final Word
Weeee that’s it for today. You have learned about what is incremental model? How to rundbt run and dbt test from your command line to BigQuery. In my next episode, I will cover the Airflow UI basics and how it can orchestrate your scheduleddbt run .
Let me know if you have any questions or comments in the comments section below. I’ll be coming soon so stay tuned!


