A Beginner’s Guide to DBT (data build tool) — Part 2 : Setup guide and tips
Installation and Data pre-processing
This is my second episode. If you are new and want to know what are the key power of DBT, you can visit my first episode on this #dbtdataseries.

Table of Contents (Updated: Aug’23)
Installation
1) Set up DBT
2) Create a BigQuery project
3) Generate BigQuery credentials
4) Create a data setData Pre-Processing
5) Clean Data before uploading to BigQuery
5.1 —olist_customers_dataset.csv5.2 —olist_order_items_dataset.csv
5.3—olist_order_reviews.csv
5.4—product_category_name_translation.csvConclusion
Final Word
1) Set up DBT
Homebrew
What is Homebrew? Homebrew is an open-source software package manager that makes it easier to install software on macOS. It’s like AppStore for installation.
1.1 Install Homebrew. Then, run:
brew update
brew install git
brew tap dbt-labs/dbtNow you’re ready to install dbt. Once you know which adapter you’re using, you can install it as dbt-<adapter>. For instance, if using BigQuery:
brew install dbt-bigqueryTest your installation with dbt --version.
Take note: The most time consuming part is
brew update, and sometimes when you runbrew updateit seems that it just stopped there, but it is actually running behind the scenes. So please do not cancelbrew updateor close your laptop; otherwise it might take longer!
2) Create a BigQuery project
2.1 Go to the BigQuery Console
2.2 Create a new project
2.3 Head back to the the BigQuery Console, and ensure your new project is selected. Please take note of your project location because later on you will need to put it into your dbt profiles.ymlconfig file.
3) Generate BigQuery credentials
3.1 Go to the BigQuery credential wizard. Ensure to choose your correct project name.

3.2 Click Create Credentials > Help me choose. Generate credentials with the following options:
- Which API are you using? BigQuery API
- What data will you be accessing? Application data
- Are you planning to use this API with App Engine or Compute Engine? No, I’m not using them
- Service account details — Service account name:
dbt-user - Grant this service account access to the project — Role: BigQuery Admin
- Grant users access to this service account — Service account admin roles: I put my gmail.
Click Done.
3.3 Go back to the BigQuery credential wizard.
3.4 Under the Service Accounts, click your newly-created service account > Go to Keys> Click Show Domain-wide Delegation> Click Create new key> Choose JSON file > Download the JSON file and save it in an easy-to-remember spot, with a clear filename (example: dbt-user-creds.json)
4) Create data set
- Once you select your project name, click
View actions>Create data set> Name your data set as accordingly.



Take note: Please take note of your project location because later on you will need to put it into your dbt
profiles.ymlconfig file. For example, I chose Singapore (asia-southeast1) as my data location.
5) Clean Data
- As mentioned above, the dataset I took is Brazilian E-Commerce Public Dataset by Olist. For this project, I will use all 9
.csvfiles except forolist_geolocation_dataset.csv - When you upload data to BigQuery from
.csvfiles, the maximum file size is 10 MB. So what I did is to trim a couple of rows so that all files are under 10 MB before the upload. - In this tutorial, I will demo the upload of 4 files —
olist_customers_dataset.csvolist_order_items_dataset.csvolist_order_reviews.csvproduct_category_translation.csvbecause each of which has a different type of error and workaround.
5.1 — olist_customers_dataset.csv
- This file is the easiest. In your newly created dataset, click
Create table> ChooseUploadand select theolist_customers_dataset.csv> Name your table ascustomers> TickAuto-detect schema.
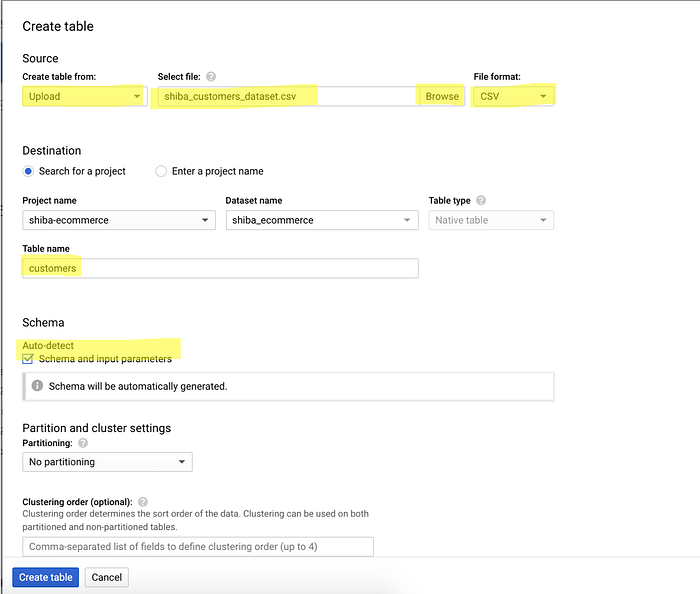
The final result should look like this.

5.2 — olist_order_items_dataset.csv
Let’s move on to the second file. Let’s select olist_order_items_dataset.csv and follow the steps as the first file.
- Error: You may likely encounter this error — seeing null values in the table
order_itemswhen importing to BigQuery. However, let’s try to click the last page, you will see non-null values. - Reason: The null values are caused by the empty rows in the
.csvfile.

- Workaround: Hence, based on my experience, the best practice is to open
.csvfiles in your code editor to check if there are any empty rows, and delete all empty rows. In the image below, I dragged theolist_order_items_dataset.csvin Visual Code Studio and delete all of the empty rows from line 51237 onwards.

- Error: You may also encounter the problem related to the
TIMESTAMPdata type. Supposedly the correct date time format in BigQuery isyyyy/mm/dd hh:mm:ss. However, as it can be seen from the columnshipping_limit_date, the date time format is00dd/mm/yy hh:mm:ss0018-01-18 02:48:00 UTC. This is not compatible in BigQuery.

- Reason: In
.csvall of the date time columns, for example, theshipping_limit_dateappears asdd/mm/yyyy hh:mm:ss. Hence, we will need to change the date format toyyyy/mm/dd hh:mm:ssto be compatible with that of BigQuery. - Workaround: To change the date format, select all rows from the
shipping_limit_datecolumn (shift + command + down arrowfor Mac) (shift + ctrl + down arrowfor Windows) > ClickMore numbers format> UnderType, change fromd/m/yy hh:mmtoyyyy/mm/dd hh:mm:ss(please see my image below for reference).
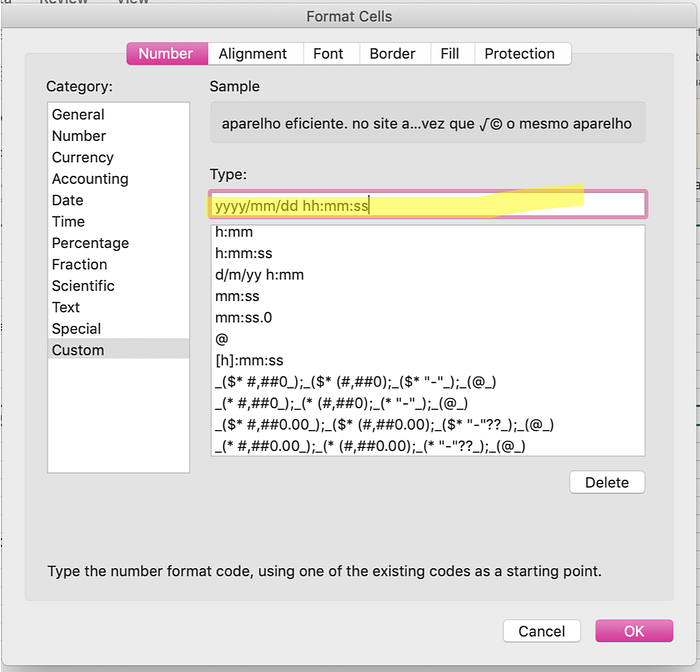
Now let’s try to import again. The result table should look like this.

5.3 — Upload olist_order_reviews.csv
Let’s move on to the third file — Now I am going to create order_reviews table from olist_order_reviews.csv file.
- Error: Then I got the error below.
Error while reading data, error message: Error detected while parsing row starting at position: 1765. Error: Missing close double quote (") character.Error while reading data, error message: CSV processing encountered too many errors, giving up. Rows: 12; errors: 1; max bad: 0; error percent: 0
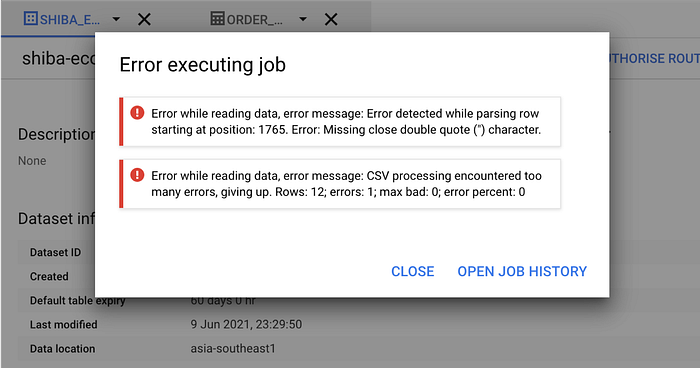
- Reason: It is due to special characters such as the double quote character
"in thereview_comment_messagecolumn. - Workaround: Therefore when you import this file, you will need to tick
Allow quoted newlinesunderAdvancedoptions.
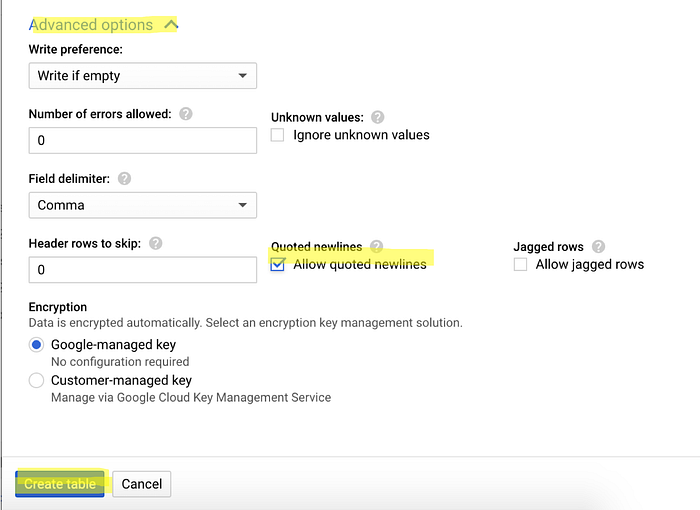
And here is the final result.
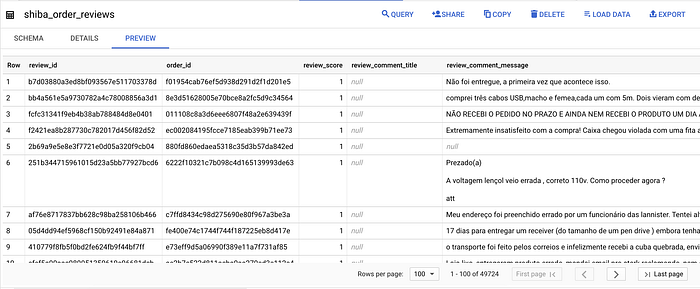
5.4 — product_category_name_translation.csv
Yayyy here’s the last file I would like to demo!
- Error: When I create a
product_category_name_translationtable fromproduct_category_name_translation.csvfile, I get incorrect column names such asstring_field_xlike shown in the image below.
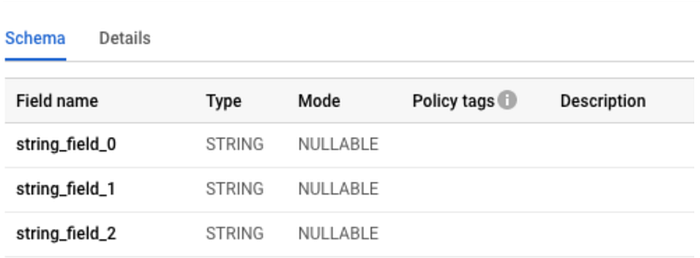
product_category_translation table- Reason: I did some research, and found the workaround from Samet Karadag (thank you!)
- Workaround: We will add a dummy integer column
intin theproduct_category_name_translationtable. Then let’s try to create theproduct_category_name_translationtable again. Now you will see that column names are recognised correctly. - The next step is to remove that
intcolumn by creating a new table using this query.
CREATE table `<project_id>.<dataset>.<table>` as
SELECT * except(int)
FROM `<project_id>.<dataset>.<table_ext>`In details
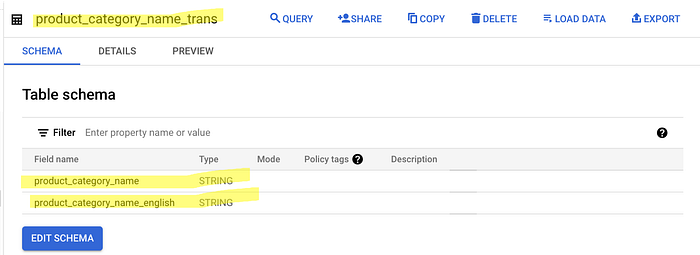
project id:shiba-ecommerce
dataset:shiba_datasettable_ext:product_category_name_translation(the initial table)
table:product_category_name_trans(the new table after removing int column)

Tadaa your final result is here!
Final Word
In summary, I have covered the installation part (how to set up DBT, create a BigQuery project at the BigQuery Console, generate BigQuery credentials at BigQuery credential wizard, create a data set) and the data pre-processing (clean data and upload data to BigQuery).
In my next episode, I will demonstrate dbt run and dbt test in details together with my struggles and workaround as well!
Stay tuned!