9 Basic Commands for PySpark SQL
In the previous post — Reading BigQuery table in PySpark, I’ve written about what PySpark is with a quick setup. In this post, I will share with you 9 basic commands for Spark SQL using Python.

Table of Contents
Introduction
Basic Commands
Summary
Introduction
Many data scientists, analysts, and general business intelligence users rely on interactive SQL queries for exploring data. And Spark SQL is a tool that enables you to do so.
What Is Spark SQL?
Apache Spark is an open-source data processing framework for processing large datasets in a distributed manner (in a cluster).
Spark SQL is a Spark module for structured data processing. One use of Spark SQL is to execute SQL queries. In this post, let’s focus on highlighting 9 basic commands of running SQL queries.
A dataset is a distributed collection of data. A DataFrame is a Dataset organised into named columns.
Basic commands
Getting to Know Spark SQL
1 — Creating a SparkSession
A SparkSession can be used to create DataFrames, register DataFrames as tables, execute SQL over tables, cache tables, and read parquet files.
# Import SparkSession from pyspark.sql
from pyspark.sql import SparkSession# Create my_spark
my_spark = SparkSession.builder.getOrCreate()
2 — Creating DataFrames
There are many ways to create DataFrames in Spark. One of the ways is from Spark Data Sources which is the example below.
# Creating DataFramesdf = spark.read.format('bigquery').option('project','<your_project_ID>').option('table',<your_table_name>).load()
3 — Inspecting Data
After you’ve created your DataFrame, I guess the next thing you may want to do is to do some quick inspect your data. Here’s a few commands!
#print the schema of df
df.printSchema()#display the content of df
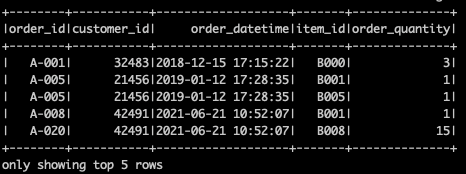
df.show()#display the first 5 rows of df
df.show(5)# Print my_spark
print(my_spark)# Print the tables in the catalog
print(spark.catalog.listTables())


Manipulating Data
4 — Creating columns
Let’s say you want to create a new column named newdf and display everything in the new DataFrame.
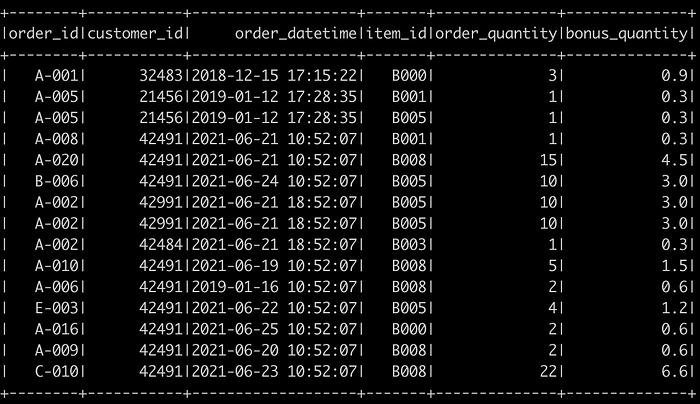
# Creating or replacing a local temporary view with this DataFrame.df.createOrReplaceTempView("people")# Define my queryquery = "SELECT *, (order_quantity*0.3) as bonus_quantity from people"newdf = spark.sql(query)#display the content of new dataframe
newdf.show()
5 — Selecting
.select
You can select a column by
newdf.select(“customer_id”).show()6 — Filtering
.filter
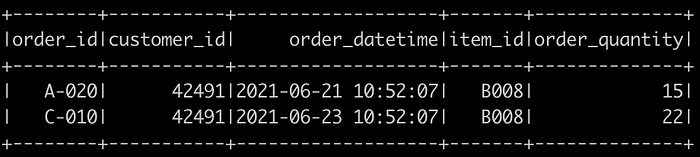
Filter the column order_id where order_quantity > 10
# Filteringdf.filter(df["order_quantity"]>10).show()
7 — Aggregating
.min() .max() .count()
All of the common aggregation methods, like .min(), .max(), and .count() are GroupedData methods. These are created by calling the .groupBy() DataFrame method. To use these functions we call that method on the DataFrame. For example, to find the minimum value of a column, col, in a DataFrame, df, you could do:
df.groupBy().min("order_quantity").show()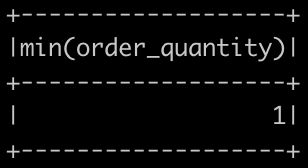
This creates a GroupedData object (so you can use the .min() method), then finds the minimum value in col, and returns it as a DataFrame.
8 — Grouping and Aggregating
.groupBy() | .avg()
For example you want to calculate average order_quantityand group by order_id
#calculate average order_quantity, group by order_id
df.groupby("order_id").avg("order_quantity").show()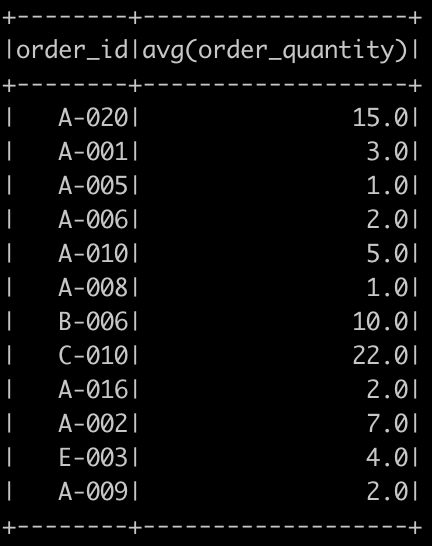
Now you’ll see that when I pass the name of one or more columns in my DataFrame to the .groupBy() method, the aggregation methods behave like when you use a GROUP BY statement in a SQL query!
SELECT order_id, avg(order_quantity)
FROM df
GROUP BY order_id9 — Running Queries Programmatically
The sql function on a SparkSession enables applications to run SQL queries programmatically and returns the result as a DataFrame.
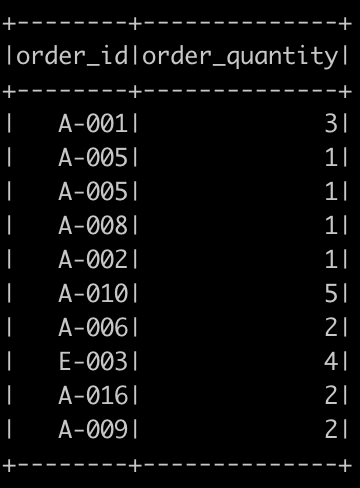
You can save DataFrame as a Temporary Table and sql query on the saved table.
# Creating or replacing a local temporary view with this DataFrame.df.createOrReplaceTempView("people")# SQL statements can be run by using the sql methodquery = "SELECT order_id, order_quantity from people where order_quantity < 10"peopleCountDf = spark.sql(query)# Display the content of dfpeopleCountDf.show()
Summary
I hope you found this article helpful. Hopefully, with this post, you can leverage your existing SQL skills to start working with Spark SQL.
The world’s fastest cloud data warehouse:
When designing analytics experiences which are consumed by customers in production, even the smallest delays in query response times become critical. Learn how to achieve sub-second performance over TBs of data with Firebolt.

